About
![]()
An open-source DataOps and dataframe-centric ETL framework for building lakehouses.
What is it?¤
Laktory is your all-in-one solution for defining both data transformations and Databricks resources. Imagine if Terraform, Databricks Asset Bundles, and dbt combined forces and added support for DataFrame API—that’s essentially Laktory.
This open-source framework streamlines the creation, deployment, and execution of data pipelines while adhering to essential DevOps practices such as version control, code reviews, and CI/CD integration. Powered by Narwhals, Laktory enables seamless transitions between Apache Spark, Polars, and other frameworks to perform data transformations reliably and at scale. Its modular and flexible design allows you to effortlessly combine SQL statements with DataFrame operations, reducing complexity and enhancing productivity.
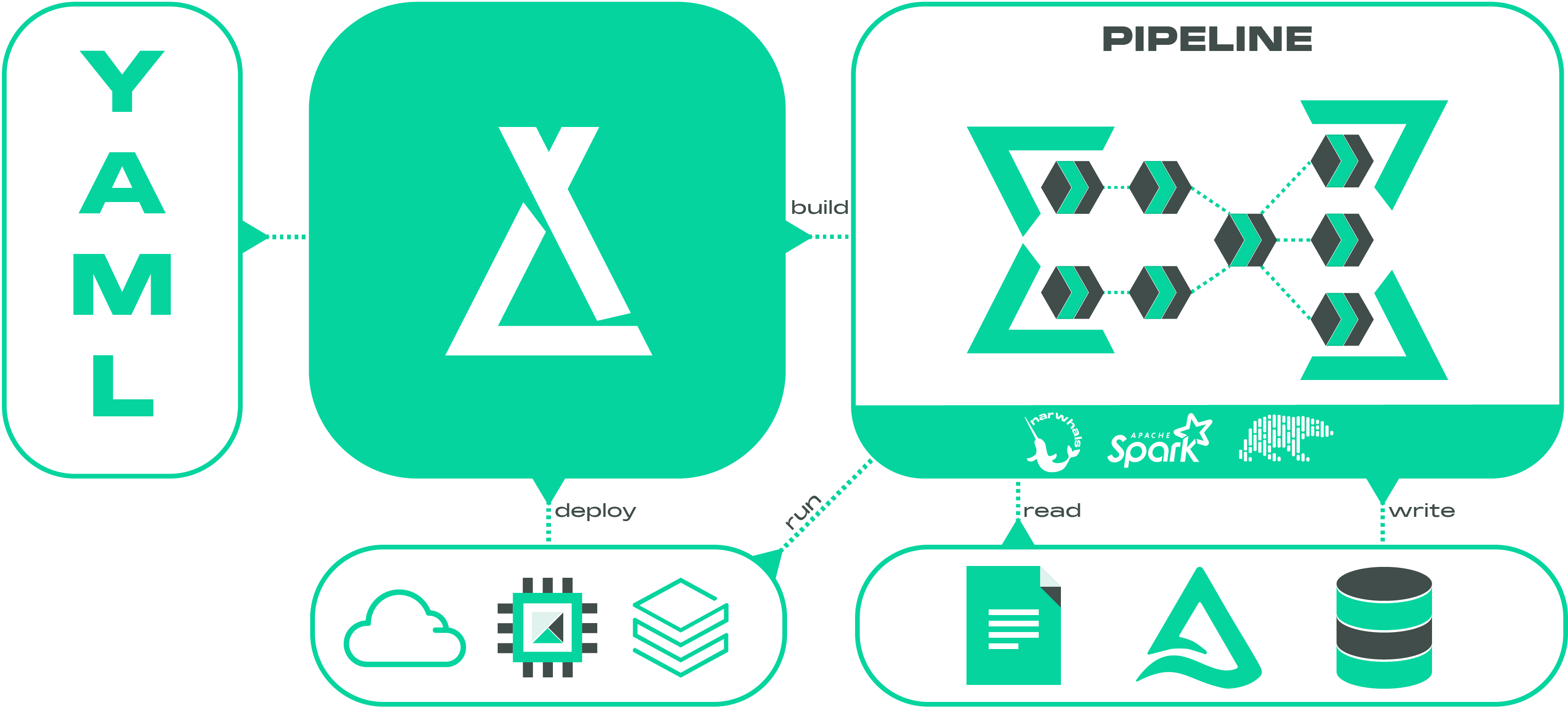
Since Laktory pipelines are built on top of Narwhals, they can run in any environment that supports python—from your local machine to a Kubernetes cluster. They can also be deployed and orchestrated as Databricks Jobs or Lakeflow Declarative Pipelines, offering a simple, fully managed, and low-maintenance solution.
But Laktory goes beyond data pipelines. It empowers you to define and deploy your entire Databricks data platform—from Unity Catalog and access grants to compute and quality monitoring—providing a complete, modern solution for data platform management.
Why Laktory?¤
Laktory is designed to accelerate value generation and reduce the total cost of operations by focusing on four key areas: simplicity, speed, scalability and quality.
Simplicity¤
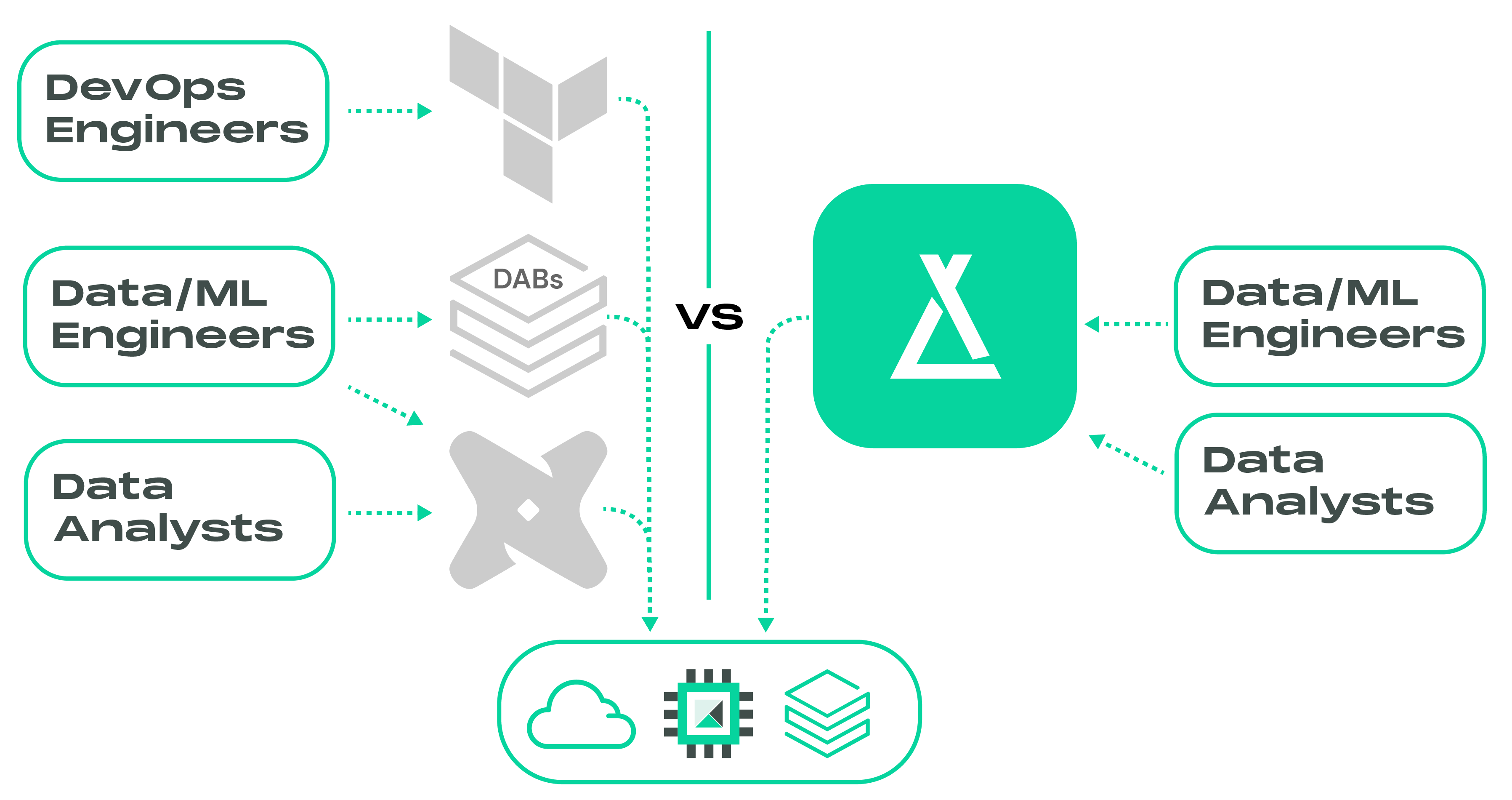
With Laktory, managing both Databricks resources and data transformations is
streamlined into a single tool. This empowers your data team to take full
ownership of the solution, eliminating the need to juggle multiple technologies.
Say goodbye to relying on external Terraform experts to handle compute, workspace
configuration, and Unity Catalog, while your data engineers and analysts try
to combine Databricks Asset Bundles and dbt to build data pipelines. Laktory
consolidates these functions, simplifying the entire process and reducing
the overall cost.
Speed¤
Adopting a DataOps approach and writing data pipelines as code enables faster, more reliable production releases. With Laktory, you can run and debug your pipelines directly from your favorite IDE before deploying to Databricks, allowing for rapid iteration. With Laktory taking care of read, write and DAG generation, you can concentrate on what matters most—business logic and creating value—while minimizing boilerplate code.

Scalability¤
Scale the right job to the right level. Run on a powerful Spark cluster when dealing with large datasets, or experiment locally with Polars on your machine with smaller ones. Switching between environments is effortless with a simple configuration change, ensuring that Laktory adapts to both small and large-scale needs without complexity.
Quality¤
Elevate data quality to a first-class citizen. Laktory integrates robust data quality expectations at both row and aggregate levels, ensuring that only trusted data reaches production analytics. Invalid records can trigger pipline failure, be dropped, or automatically quarantined for later review.
Who is using it?¤
A growing number of businesses rely on Laktory to build, deploy, and scale their lakehouses with confidence.




Curious about their experience? Read their testimonials.
How does it work?¤
Using YAML configuration files or python code, define a stack of resources, such as a data pipelines with SQL-based and Spark-based transformations.
Declare¤
name: slv_stock_prices
dataframe_backend: PYSPARK
source:
path: /Volumes/dev/sources/landing/tables/brz_stock_prices/
format: JSON
sinks:
- schema_name: finance
table_name: slv_stock_prices
transformer:
nodes:
- expr: |
SELECT
data.created_at AS created_at,
data.symbol AS symbol,
data.open AS open,
data.close AS close,
data.high AS high,
data.low AS low,
data.volume AS volume
FROM
{df}
- func_name: drop_duplicates
func_kwargs:
subset:
- symbol
- timestamp
...
from laktory import models
node = models.PipelineNode(
name="slv_stock_prices",
dataframe_backend="PYSPARK",
source=models.FileDataSource(
path="/Volumes/dev/sources/landing/tables/brz_stock_prices/",
format="JSON",
),
sinks=[
models.UnityCatalogDataSink(
schema_name="finance",
table_name="slv_stock_prices"
)
],
transformer=models.DataFrameTransformer(
nodes=[
{"expr": """
SELECT
data.created_at AS created_at,
data.symbol AS symbol,
data.open AS open,
data.close AS close,
data.high AS high,
data.low AS low,
data.volume AS volume
FROM
{df}
"""},
{
"func_name": "drop_duplicates",
"func_kwargs": {
"subset": ["symbol", "created_at"]
}
}
]
)
)
Debug¤
Execute your pipline from your IDE using python and a local or remote Spark session.
from databricks.connect import DatabricksSession
from laktory import models
from laktory import register_spark_session
with open("pipeline_node.yaml") as fp:
node = models.PipelineNode.model_validate(fp)
spark = DatabricksSession.builder.getOrCreate()
register_spark_session(spark)
node.execute()
node.output_df.laktory.display()
print(node.output_df.to_native().show())
from databricks.connect import DatabricksSession
from laktory import register_spark_session
spark = DatabricksSession.builder.getOrCreate()
register_spark_session(spark)
node = ...
node.execute()
node.output_df.laktory.display()
print(node.output_df.to_native().show())
[laktory] Executing pipeline node slv_stock_prices
[laktory] Reading `PipelineNodeDataSource` brz_stock_prices with DataFrameBackends.PYSPARK
[laktory] Reading pipeline node brz_stock_prices from output DataFrame
[laktory] Read completed.
[laktory] Executing DataFrame Transformer
[laktory] Executing DataFrame transformer node 0 (DataFrameExpr).
[laktory] DataFrame as
SELECT
CAST(data.created_at AS TIMESTAMP) AS created_at,
data.symbol AS name,
data.symbol AS symbol,
data.open AS open,
data.close AS close,
data.high AS high,
data.low AS low,
data.volume AS volume
FROM
{df}
[laktory] Executing DataFrame transformer node 1 (DataFrameMethod).
[laktory] Applying df.unique(subset=['symbol', 'created_at'],keep=any)
[laktory] Writing static df to ./data/slv_stock_prices.parquet with format 'PARQUET' and {}
[laktory] Write completed.
┌────────────────┬───────┬────────┬────────────┬────────────┬────────────┬────────────┬────────────┐
│ created_at ┆ name ┆ symbol ┆ open ┆ close ┆ high ┆ low ┆ volume │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ datetime[μs] ┆ str ┆ str ┆ f64 ┆ f64 ┆ f64 ┆ f64 ┆ f64 │
╞════════════════╪═══════╪════════╪════════════╪════════════╪════════════╪════════════╪════════════╡
│ 2023-04-04 ┆ AMZN ┆ AMZN ┆ 103.175003 ┆ 103.129997 ┆ 103.419998 ┆ 103.072502 ┆ 3.998703e6 │
│ 13:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ 2023-04-06 ┆ MSFT ┆ MSFT ┆ 288.859985 ┆ 290.360107 ┆ 291.070007 ┆ 288.700012 ┆ 4.355298e6 │
│ 13:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ 2023-03-02 ┆ AMZN ┆ AMZN ┆ 90.589996 ┆ 90.860001 ┆ 91.004997 ┆ 90.529999 ┆ 4.143251e6 │
│ 12:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ 2023-10-03 ┆ AMZN ┆ AMZN ┆ 125.150002 ┆ 125.580002 ┆ 125.699997 ┆ 124.800003 ┆ 5.416032e6 │
│ 11:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ 2024-03-05 ┆ AAPL ┆ AAPL ┆ 170.785004 ┆ 170.470001 ┆ 170.828705 ┆ 170.149994 ┆ 4.315788e6 │
│ 12:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
│ 2023-11-30 ┆ AAPL ┆ AAPL ┆ 188.335007 ┆ 188.789993 ┆ 188.830002 ┆ 188.289993 ┆ 2.75059e6 │
│ 13:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ 2023-03-22 ┆ MSFT ┆ MSFT ┆ 275.850006 ┆ 277.049988 ┆ 277.149994 ┆ 275.764008 ┆ 1.790997e6 │
│ 12:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ 2023-01-12 ┆ GOOGL ┆ GOOGL ┆ 91.480003 ┆ 91.510002 ┆ 91.870003 ┆ 89.75 ┆ 7.320764e6 │
│ 09:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ 2023-07-20 ┆ GOOGL ┆ GOOGL ┆ 120.459999 ┆ 120.059998 ┆ 120.470001 ┆ 119.764999 ┆ 2.94552e6 │
│ 12:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ 2023-08-22 ┆ AAPL ┆ AAPL ┆ 176.922897 ┆ 177.214996 ┆ 177.429993 ┆ 176.310104 ┆ 6.823573e6 │
│ 10:30:00 ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
└────────────────┴───────┴────────┴────────────┴────────────┴────────────┴────────────┴────────────┘
Deploy¤
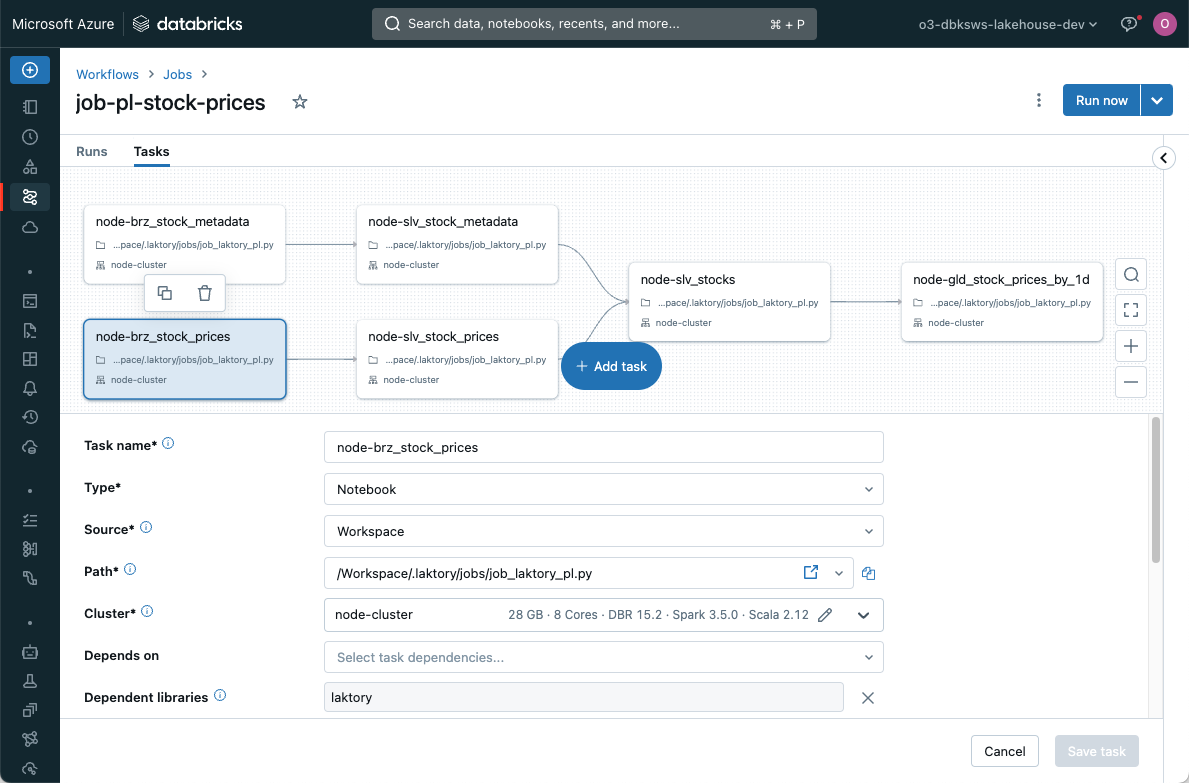
Preview, deploy and run your stack using the CLI
laktory deploy --env dev
laktory run --env dev --dbks-job slv_stock_prices
Watch it¤
See it in actions in this introduction video:
Who is it for?¤
Laktory is built by data engineers for data engineers. It does not have visual interface nor allow you to setup pipelines with a few clicks and some drag and drop. On the other hand, if you have minimal DevOps or programming experience, you will be able to efficiently scale, deploying hundreds of datasets and models without compromising data governance. It also provides you with the tools for building a UI within your organization for a fully self-served experience.
Okube¤
![]()
Laktory is one of the kubes developed by Okube, a company dedicated to building open source frameworks, empowering businesses to build, deploy and operate highly scalable data platforms and AI models.
Partners¤
Okube and Laktory are official Databricks Technology Partners
![]()
Learn more in our Partners sections.